Шаг 1. Регистрируемся
Первым шагом в раскрутке является регистрация на сайтах, которые ведут реестр ресурсов по определенным параметрам, и установка на собственном сайте счетчика. Такую регистрацию необходимо проводить на популярных интернет-ресурсах, посещаемость которых превышает 10 тыс. пользователей в день (например, www.bigmir.net, www.meta.ua, www.i.ua, www.rambler.ru, www. yandex.ua и др.). Регистрации на пяти подобных сайтах будет более чем предостаточно.
Шаг 2. Ловушка для робота
Засветив наш ресурс в Интернете, перейдем к следующему шагу. Все поисковые роботы при заходе на сайт в первую очередь ищут файл robots.txt. Поэтому для начала в корне ресурса необходимо создать файл robots.txt и дать на него права доступа на чтение для всех. Затем нужно наполнить файл смысловым содержанием, понятным для поисковых роботов. Содержание файла должно быть следующего характера:

Назначение команд и переменных в данном файле несут поисковому роботу следующую информацию: User-agent: * – доступ и индексирование на данном ресурсе разрешается всем поисковым роботам; Disallow – запрещается посещать и индексировать поисковым роботам папки. Это нужно для ограничения доступа к какой-то части ресурса. В данной конфигурации ограничивается доступ к папкам ресурса: cgi-bin, admin, files, images, styles и subs.
Шаг 3. Прописывание META-тегов
На этом этапе необходимо определить ключевые слова — «META-теги» — для стартовой и всех остальных страниц сайта. Почему это имеет такую важность? Поисковый робот, заходя на ресурс для индексирования, не определяет, какой части пользователей данный ресурс будет интересен. Он проверяет, какие слова часто встречаются, выясняет ключевые слова ресурса и вносит их в свой реестр. Зачастую это не соответствует направленности ресурса. Ведь чтобы в последующем ресурс был посещаемым и правильно отображался на поисковых сайтах, необходима его корректная индексация. А кто, как не владелец, знает, какую информацию несет его ресурс и для кого она предназначается?
Примечание: Максимальное количество ключевых слов, которое можно размещать на одной странице, не должно превышать двадцати.
Обозначив на бумаге все ключевые слова, их необходимо правильно прописать на каждой странице. Какие же бывают META-теги и как их правильно прописывать?
META-теги — это конструкции, которые размещаются в заголовке страницы и выглядят примерно так:
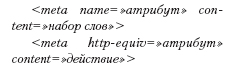
Поле name определяет, за что именно данный тег отвечает. Длина каждого поля content по стандарту ограничена килобайтом (1024 знака, включая пробелы и знаки препинания), однако у каждой поисковой системы обычно свои взгляды на это. Надо помнить, что META-теги включены в код страницы, так что увеличение их длины ведет к росту объема страницы, а следовательно, к увеличению времени загрузки. Поле http-equiv означает, что данный META-тег предназначен для управления браузером на стороне клиента.
Как выглядят META-теги для текущей страницы, можно посмотреть, щелкнув правой кнопкой мыши по листу и выбрав «Просмотр в виде HTML» (в Internet Explorer) или же «Просмотр исходного кода страницы» (в Mozilla Firefox).
Рассмотрим основные META-теги и опишем, за что они отвечают.
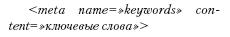
Зачастую именно то, что указано здесь, будет отображаться поисковиками в выдаче результатов поисковых запросов (сниппетах). Поэтому описание следует делать ярким и точным, однако не стоит писать его прописными буквами – умные поисковые машины считают это спамом и «выпендрежем», и такие страницы могут пессимизировать в результатах поиска. Несмотря на то что на данный момент это один из действительно полезных тегов, вполне можно обойтись и без него – правильного хорошего заголовка страницы вполне достаточно.
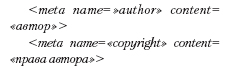
На первый взгляд, это самый эффективный и важный тег из набора МЕТА-тегов. Именно по тем словам, которые здесь будут прописаны, и должна находиться страница в результатах выдачи поисковых систем.
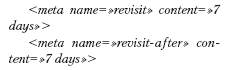
Эти теги, исходя из их описания, должны давать команду поисковой системе посещать данную страницу сайта так часто, как это прописано (в данном случае каждые 7 дней). На деле каждый поисковый робот заходит на сайт с частотой, которую сам посчитает нужной и возможной. Частота зависит от показателя цитируемости документа: чем этот показатель выше, тем чаще будет приходить поисковый робот. Например, главную страницу сайта Googlebot (поисковый робот Google) посещает несколько раз в день.
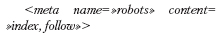
Еще один тег, отвечающий за управление поисковыми роботами. Вот какие могут быть значения у поля содержимого: index – индексировать эту страницу, follow – индексировать страницы, на которые есть ссылки с этой страницы, all – эквивалентно двум предыдущим через запятую, noindex – не индексировать страницу, но идти по ссылкам, nofollow – индексировать, но не идти по ссылкам, none – эквивалентно двум предыдущим через запятую. Нужно ли использовать этот тег? Можно создать файл robots.txt, в котором все это прописать, не перегружая ненужными данными код страницы.
Совершенно необязательные теги, в которые можно вписать собственное имя, название студии, личный e-mail, описание авторских прав на документ, предпочитаемый сорт пива или имя любимой собаки. В основном используются по незнанию или чтобы найти в Интернете копии оригинальных страниц, «содранных» неопытными и бестактными пользователями. Формат записи произвольный.
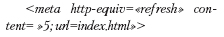
Данная конструкция через пять секунд после прочтения браузером страницы, на которую вы попали, перегрузит окно браузера и выдаст страницу index.html из текущего каталога сервера. Чаще всего данный тег используется на страницах, которые вставляются вместо титульных при переезде сайта на другой адрес – таким образом осуществляется автоматическая пересылка. Однако того же можно достичь с помощью команды самому серверу, причем сделать это мгновенно, так что пользователь и не заметит, что загруженная страница находится совершенно по другому адресу.
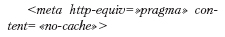
Тег контролирует занесение страниц в кеш-память компьютера. Страницы с ним не будут кешироваться браузерами. Однако современные версии браузеров сами умеют или должны уметь распознавать, обновилась страница или нет, и если надо, обновлять ее безо всяких на то дополнительных ухищрений со стороны автора сайта.
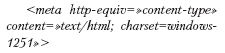
Конструкция предписывает, в какой кодировке выдавать пользователю запрошенную страницу. Однако определять правильную кодировку должен либо сервер, либо браузер. Впрочем, первые иногда бывают не настроены на это ленивыми системными администраторами, а вторые — плохо в этом разбирающимися пользователями.
Можно сделать вывод, что использование всех тегов не имеет никакого смысла, а наоборот ухудшает работу сайта. Важно прописать лишь необходимые МЕТА-теги, а именно:

Их будет достаточно для описания ключевых слов и назначения сайта.
Шаг 4. Ссылки извне
Самый рутинный шаг — это добавление информации о сайте на форумы, доски объявления. Но если его не выполнить, то раскрутка сайта не будет столь эффективной. Чтобы прояснить ситуацию, перечислим факторы, которые влияют на эффективность индексирования сайта:
- количество ресурсов, имеющих ссылки на сайт;
- наличие уникального и релевантного содержания;
- возможность успешно просканировать страницы.
Для поднятия сайта вверх по статистике поисковых ресурсов и его появления на первых местах, прежде всего, нужно, чтобы как можно больше сайтов ссылались на него. Это можно выполнить, только размещая информацию на форумах и досках объявлений. Так как посещаемость их очень велика, индексирование этих сайтов производится постоянно. А добавить данные на них можно бесплатно (сразу же или после регистрации).
Шаг 5. Google — всему голова?
Самый сложный и самый эффективный шаг по раскрутке сайта – это его регистрация и размещение информации в поисковой системе Google.
К счастью, в результаты поиска Google сайты включаются бесплатно. Чтобы проверить, включен ли сайт в индекс, выполните в Google поиск URL-адреса своего сайта. При этом поисковик сканирует миллиарды страниц, но некоторые все же может пропустить. Если поисковые машины пропускают сайт, это может быть вызвано одной из следующих причин:
- ресурс недостаточно хорошо связан многочисленными ссылками с другими сайтами в Интернете;
- сайт запущен после последнего сканирования роботами Google;
- структура ресурса затрудняет эффективное сканирование его содержания;
- когда поисковые роботы пытались просканировать сайт, он оказался временно недоступен либо поисковые роботы столкнулись с ошибкой. С помощью инструментов для веб-мастеров Webmaster Tools от Google (www.google.com.ua/webmasters/) можно узнать, не возникли ли ошибки при попытке сканирования сайта.
Для облегчения индексации поисковым роботом сайта нужно передать в Google его подробную карту. Это делается с помощью файла sitemap.xml, который помещается в корень сайта. Sitemap.xml – это простой способ передать URL в индекс Google и получить подробные отчеты о показах ваших страниц в этой поисковой системе. С помощью данной функции пользователи могут автоматически информировать Google обо всех своих страницах и вносимых изменениях.
Файлы Sitemap особенно полезны в следующих случаях:
- на сайте имеется динамически обновляемый контент;
- ресурс содержит страницы, которые поисковому роботу сложно обнаружить в процессе сканирования, например страницы, содержащие большое число Flash-компонентов;
- сайт новый и на него мало ссылок;
- ресурс имеет большой архив содержательных страниц, не связанных или слабо связанных друг с другом.
Компания Google руководствуется протоколом Sitemap версии 0.9, согласно определению sitemaps.org. Таким образом, файлы Sitemap, создаваемые для Google с использованием протокола sitemap 0.9, совместимы с другими поисковыми системами, поддерживающими стандарты sitemaps.org.
Примечание: Передача sitemap.xml не гарантирует, что все страницы сайта будут просканированы или включены в результаты поиска.
Выполнив все перечисленные шаги, остается ждать результата. Однако он придет не сразу же. Минимальный период времени, через который сайт начнет нормально индексироваться поисковиками и отображаться среди первых 40 позиций поисковых результатов, составляет около месяца. При условии, что все эти шаги будут постоянно поддерживаться и контролироваться, сайт в течение полугода может попасть в первую десятку.

